玩转 javascript 正则表达式
正则表达式是什么
正则表达式可以从一段文本中提取特定内容的功能, 几乎所有编程语言都支持. 使用在爬虫、检查用户输入合法性、XSS 过滤等.
在整个学习过程中, 给大家推荐一个可视化正则表达式的网站 https://jex.im/regulex/
他可以根据你输入的正则表达式动态的生成匹配图, 帮助你理解一个复杂的正则表达式. 像下面这样
**更新(2023-07-07)**:现在推荐这个网站,它支持最新的具名分组和后行断言语法 https://wangwl.net/static/projects/visualRegex
语法
javascript 中支持 3 种正则表达式语法: 字面量、构造函数和工厂符号, 他们的签名如下
/pattern/flags
new RegExp(pattern, [, flags])
RegExp(pattern, [, flags])
pattern
正则表达式的匹配文本, 支持的内容有普通字符(如 abcd 0123 等)与特殊字符(如 \w{1,4} (\n+) .* 等)
flags
修饰标志. 有以下的任意组合
g: 全局匹配. 找到所有匹配, 而不是在第一个匹配后停止.i: 忽略大小写.m: 多行匹配. 作用与开始字符(^)和结束字符($), 视为在每一行中匹配而非在整串文本中匹配.u: (*ES2015) 用于正确处理大雨\uFFFF的 Unicode 模式.y: (*ES2015) 粘性匹配. 与g相似, 仅匹配此正则表达式的lastIndex属性指示的索引之后的子串.s: (*ES2018) dotAll 模式. 将.符号修改为匹配任意字符
例如, 下面的三行语句将创建相同的正则表达式, 他们将匹配 abcd ABBBc 0AbC 等.
1 | /ab+c/i |
正则表达式的构造函数提供了正则表达式运行时编译. 所以如果你事先不知道将要使用什么模式进行匹配, 你可以使用构造函数传入变量的方法进行匹配, 如
1 | var pattern = 'ab+c' |
需要注意的是, 当使用字符串构造正则表达式时, 需要将字符串中的特殊字符进行转义(在前面加反斜杠 \), 如下面两行是等价的
1 | new RegExp('\\w+') |
特殊字符
这里只作为速查食用, 如需详细解释请前往 MDN RegExp 文档
字符类别 Character Classes
.匹配任意单个字符,但是行结束符除外. 在集合[]中,.将被解释作字面量含义\d匹配任意阿拉伯数字. 等价于[0-9].\D匹配任意一个不是阿拉伯数字的字符. 等价于[^0-9].\w匹配字母表中的字母、数字和下划线. 等价于[A-Za-z0-9_]\W匹配非字母表中的字母、数字和下划线. 等价于[^A-Za-z0-9_]\s匹配一个空白字符. 等价于[ \f\n\r\t\v]和一些 Unicode 空格\S匹配一个非空白字符. 等价于[^ \f\n\r\t\v]和一些 Unicode 空格\t匹配一个水平制表符(tab)\r匹配一个回车符(carriage return)\n匹配一个换行符(linefeed)\v匹配一个垂直制表符(vertical tab)\f匹配一个换页符(form-feed)[\b]匹配一个退格符(backspace)(不要与\b混淆)\0匹配一个 NUL 字符. 不要在此后面跟小数点.\cXX 是 A-Z 的一个字母. 匹配字符串中的一个控制字符.\xhh匹配编码为 hh (两个十六进制数字)的字符.\uhhhh匹配 Unicode 值为 hhhh (四个十六进制数字)的字符.\p{Name}(*ES2018) 匹配符合 Unicode 某属性的所有字符. 参见这里\转义符. 将特殊字符转化为字面量含义.
字符集合 Character Set
[xyz]一个字符集合,也叫字符组. 匹配集合中的任意一个字符. 你可以使用连字符-指定一个范围.[^xyz]一个反义或补充字符集,也叫反义字符组. 也就是说,它匹配任意不在括号内的字符. 你也可以通过使用连字符 ‘-‘ 指定一个范围内的字符.
边界 Boundaries
^匹配输入开始. 如果多行修饰符m被开启,该字符也会匹配一个断行符后的开始处.$匹配输入结尾. 如果多行修饰符m被开启,该字符也会匹配一个断行符的前的结尾处.\b匹配一个零宽单词边界,如一个字母与一个空格之间. (不要和 [\b] 混淆)\B匹配一个零宽非单词边界,如两个字母之间或两个空格之间.
分组与反向引用 Group & Back Reference
(x)捕获括号. 匹配x并捕获匹配项.\n反向引用. n 是一个正整数, 指向正则表达式中的第 n 个括号中匹配的子串.(?:x)非捕获括号. 匹配x但不捕获, 用于分组.(?<name>x)(*ES2018) 具名分组. 匹配x并将捕获到的组可以name属性访问. 参考这里
量词 Quantifiers
x{n}n 为正整数, 匹配x连续出现 n 次x{n,}n 为正整数, 匹配x至少连续出现 n 次x{n,m}n,m 为正整数, 匹配x至少连续出现 n 次, 至多出现 m 次x*匹配前面的模式x0 或多次.x+匹配前面的模式x至少出现 1 次. 等价于x{1,}x*?非贪婪模式匹配x*(有关贪婪模式)x+?非贪婪模式匹配x+(有关贪婪模式)x?匹配x0 或 1 次. 等价于x{0,1}x|y匹配x或y
断言 Assertions
x(?=y)只有当x在y前面时,才匹配x.x(?!y)只有当x不在y前面时,才匹配x.x(?<=y)(*ES2018) 后行断言. 只有当x在y后面时,才匹配x.x(?<!y)(*ES2018) 后行断言. 只有当x不在y后面时,才匹配x.
注: 断言的部分是不在匹配结果中的
注: 后行断言中的部分将会在组中以从右到左的方式计算引用
常用的正则表达式参考
汉字
1 | /[\u4e00-\u9fa5]/ |
手机号码
1 | /^1[3456789]\d{9}$/ |
身份证号码
1 | /(^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$)|(^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}$)/ |
注: 不要依赖正则表达式来校验身份证号码, 正则只用来验证格式, 无法验证校验码
Email 地址
1 | /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/ |
HTTP URL
1 | /^(https?|ftp|file):\/\/[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]$/ |
Regex Tuesday 挑战
好了, javascript 中的正则表达式差不多就到这里了, 如果有实战兴趣的话, 不妨来挑战一下?
Regex Tuesday (可能需要科学上网)
下面是自己做的 regex-tuesday 答案
Week 1. Repeated words
考察点: 反向引用 边界
查看答案
这个比较简单
1 | /(\b\S+\b) (\b\1\b)/gi // pattern |
Week 2. Grayscale colours
考察点: 反向引用 分组 量词
查看答案
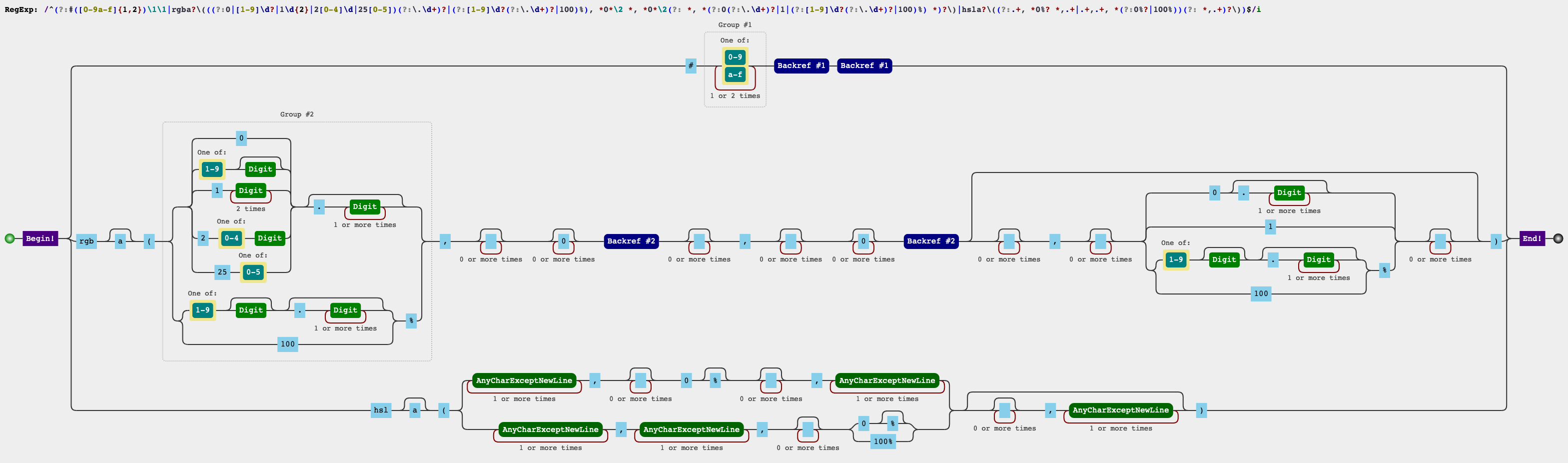
这个可怕的正则表达式
1 | /^(?:#([0-9a-f]{1,2})\1\1|rgba?\(((?:0|[1-9]\d?|1\d{2}|2[0-4]\d|25[0-5])(?:\.\d+)?|(?:[1-9]\d?(?:\.\d+)?|100)%), *0*\2 *, *0*\2(?: *, *(?:0(?:\.\d+)?|1|(?:[1-9]\d?(?:\.\d+)?|100)%) *)?\)|hsla?\((?:.+, *0%? *,.+|.+,.+, *(?:0%?|100%))(?: *,.+)?\))$/i // pattern |
Week 3. Dates
查看答案
考察点: 分组
1 | /^(1\d{3}|200\d|201[0-2])\/(0[1-9]|1[0-2])\/(0[1-9]|[1-2]\d|30) ([01]\d|2[0-3]):([0-5]\d)(?::([0-5]\d))?$/ |

Week 4. Italic Markdown
查看答案
1 | // 普通版本 |